We're Good At Recognizing Distorted Faces
Author Vishay SinghPosted on Categories Discover Magazine
A new paper from MIT neuroscientists Sharon Gilad-Gutnick and colleagues reveals that we are remarkably good at recognizing faces even if they are highly distorted. Not only is this scientifically interesting, the deformed images used in this study are rather hilarious.
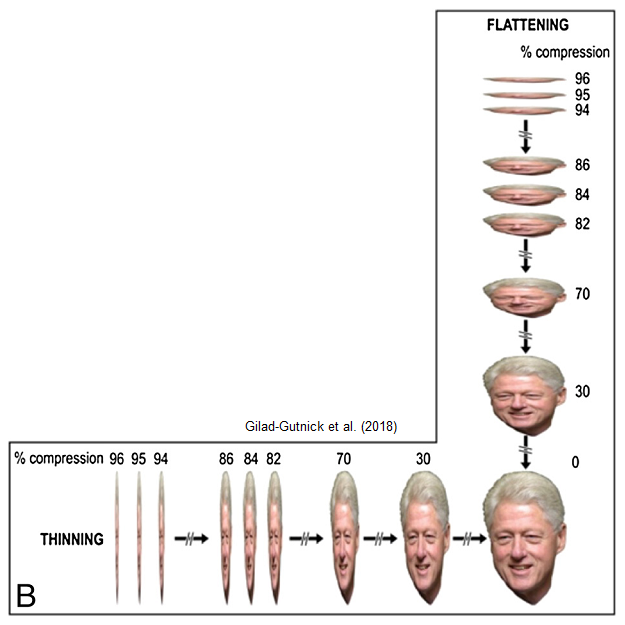
Here’s an example of a face being distorted by horizontal and vertical compression (also known as thinning and flattening). The unfortunate victim of these distortions is Bill Clinton:
Gilad-Gutnick et al. found that people are very good at recognizing thinned and flattened celebrity faces. In fact, a thinning or flattening of as much as 80% has almost zero impact on recognition accuracy. Beyond 80%, performance starts to fall off, but even at a distortion level of 90% – in which the face is reduced to a mere ‘sliver’ – volunteers were still able to recognize about half of the celebrities.
The authors speculate that our face recognition system needs to be robust to compression in this way, because of perspective: when we see someone’s face from an angle, the features appear compressed.
Next, Gilad-Gutnick et al. wanted to know which parts of the face were most important in terms of recognition. This led to them to create some – well – amusing stimuli:
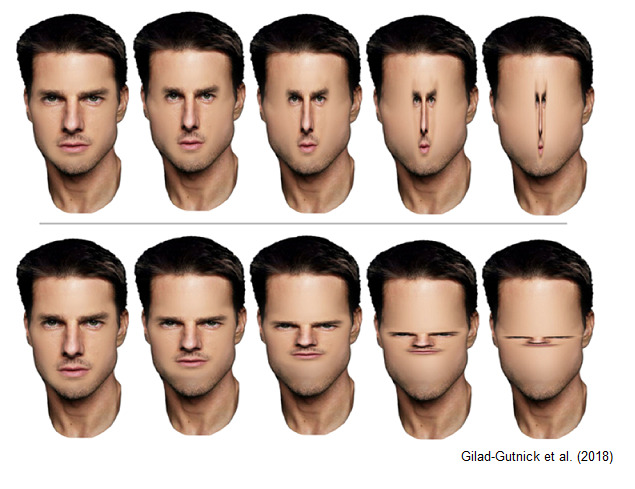 Here we see the selective compression of the ‘internal features’ of Tom Cruise’s face, while the ‘external features’ are left untouched. This produces bizarre images which call to mind a certain genre of internet memes, like this one I found:
Here we see the selective compression of the ‘internal features’ of Tom Cruise’s face, while the ‘external features’ are left untouched. This produces bizarre images which call to mind a certain genre of internet memes, like this one I found:

Anyway, it turned out that selective vertical compression of ‘internal features’ badly impairs recognition accuracy. In other words, while it is easy to recognize someone if their whole face is vertically compressed, it is much harder when only their eyes, nose and mouth are squashed. This isn’t true for horizontal compression.
Check out the Tom Cruise examples above: the bottom row looks less like Cruise than the top row, I think.
Gilad-Gutnick et al. interpret this finding as suggesting that vertical ‘within-axis distance ratios’ are key to facial recognition. If we compress the whole face, the relative distances between, say, the eyes, nose, and hairline don’t change. But if we only compress the internal features, these ratios are altered.