Spreadsheet Risks in Science
Author Vishay SinghPosted on Categories Discover Magazine
Errors in the use of spreadsheets such as Microsoft Excel could pose risks for science.
That’s according to a preprint posted on arXiv from Ghada AlTarawneh and Simon Thorne of Cardiff Metropolitan University.
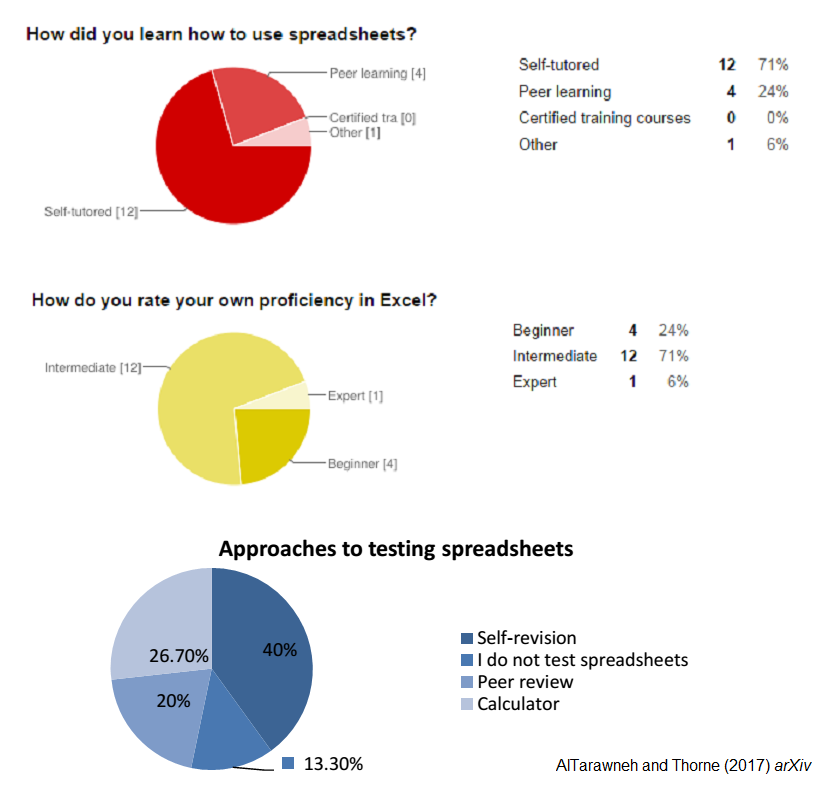
AlTarawneh and Thorne conducted a survey of 17 researchers from the University of Newcastle neuroscience research centre, ranging from PhD students to senior researchers. None of the respondants had any formal, certified training in spreadsheet use, with most (71%) being self-taught. Despite this, the majority of the researchers rated themselves as “intermediate” users of Excel.
Worryingly, only 20% reported that they had their spreadsheets checked for errors by colleagues (‘peer reviewed’). Most said they did all the testing themselves, or even that they did none at all.
As AlTarawneh and Thorne comment, these results raise the possibility that researchers may have a tendency towards overconfidence in their use of spreadsheets:
Superficially, spreadsheets seem to be simple and straightforward tools but error rates show they carry significant risk… overconfidence tends to increase specially in people who are highly educated.
Although this was a very small study, the results absolutely ring true to me. I’ve been using Excel since the first year of my PhD, and the vast majority of my colleagues also use it heavily. Very few of us have any formal training. In fact, people come to me for Excel tips, even though I’m entirely self-taught, and I have caught myself making numerous mistakes in my own spreadsheets (and how many are there that I don’t know about?)
I previously wrote about my first major Excel blooper, which generated a spurious positive result by chance, during my PhD:
In my data, as in most people’s, each row was one sample (i.e. a participant) and each column was a variable. What had happened was that at some point I’d tried to take all the data, which was in no particular order, and reorder (sort) the rows alphabetically by subject name to make it easier to read.
How could I screw that up? Well, by trying to select “all the data” but actually only selecting some of the columns. I must have reordered them, but not the others, so all the rows became mixed up.
I’ve been more careful since then, but just the other week I found out about another error I had made in a sheet I created three years ago. This Excel sheet was set up to calculate the total score on a questionnaire based on the raw items. The formulas in the sheet were all working as designed, but I had misunderstood how the questionnaire was meant to be scored, so my design was wrong. I only spotted the error after revisiting the old spreadsheet for an unrelated reason.
Fortunately, I caught both of the errors described above before the data in question had been published, so I didn’t need to correct or retract any papers. But if I had submitted the miscalculated data for publication, I doubt the peer reviewers would have spotted it. In neuroscience, it is very rare for reviewers to inspect the raw datasheets for errors, or even to have access to them. A worrying situation, indeed.