Is Neuroscience Underpowered? “Power Failure” Revisited
Author Vishay SinghPosted on Categories Discover Magazine
Back in 2013, a Nature Reviews Neuroscience paper appeared called Power failure: why small sample size undermines the reliability of neuroscience. This paper got a lot of attention at the time and has since been cited a dizzying 1760 times according to Google.
{kind=link}
‘Power Failure’ made waves for its stark message that most neuroscience studies are too small, leaving neuroscience lacking statistical power, the chance of detecting signal in the noise. As the authors Kate Button et al. wrote
The average statistical power of studies in the neurosciences is very low. The consequences of this include overestimates of effect size and low reproducibility of results.
Now, four years later, a new paper in the Journal of Neuroscience takes a fresh look at the issue. British authors Camilla Nord et al. reanalyzed the same dataset from Button et al. The key finding of the new study is that the field of neuroscience is diverse in terms of power, with some branches of neuroscience doing relatively well.
Here’s the headline result: a histogram showing the distribution of power in all 730 studies from 49 meta-analyses:
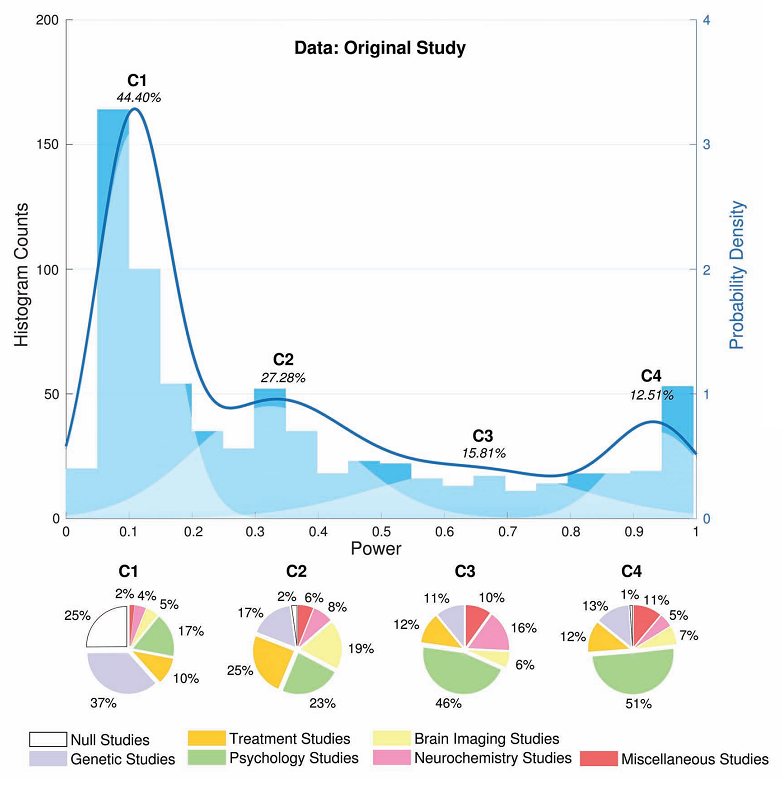
This shows a broad distribution of power. There’s a large peak of very low powered studies, but plenty of well-powered studies too, and everything in between.
Using mixture modelling, Nord et al. broke down the 730 studies into four statistical categories, labelled C1 to C4. A look at the nature of the studies within each category revealed some interesting differences (shown as pie charts above.)
The C1 component, accounting for nearly half of the studies in Button et al., had extremely low power. However, many of the studies in C1 weren’t really ‘neuroscience’ as such. 37% of C1 consisted of genetic association studies – and these were mostly the kind of ‘candidate gene‘ study that, while popular 10 years ago, are now regarded with great skepticism.
What’s more, ‘null studies’ accounted for 25% of C1. Null studies were those which studied an effect that turned out not to exist (according to the meta-analysis the study formed part of.) The concept of statistical power doesn’t really apply to null studies, so these probably shouldn’t have been included in Button et al., although it wouldn’t have changed their results dramatically.
The other components, C2 to C4, were pretty similar and contained a mixture of non-genetic, non-null studies such as neuroimaging and psychology studies. Overall, it appears that the power situation is not quite as bad as Button et al. reported, and there is a lot of diversity even within each branch of the field:
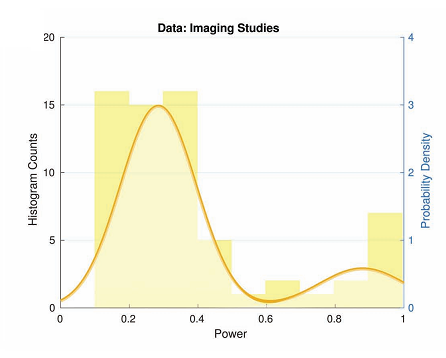 Nord et al. conclude that
Nord et al. conclude that
We argue that a very influential analysis (cited over 1500 times at the time of writing) does not adequately describe the full variety of statistical power in neuroscience… Our analyses do not negate the importance of the original work in highlighting poor statistical practice in the field, but they do reveal a more nuanced picture…
We confirm that low power is clearly present in many studies, and agree that focusing on power is a critical step in improving the replicability and reliability of findings in neuroscience. However, we also argue that low statistical power in neuroscience is neither consistent nor universal.
That said, the picture is still pretty worrying. The vast majority of studies do have a power well below the 80% theshold that’s considered desirable. In my view, this has to be a problem, although it’s difficult to say what the distribution of power ‘should’ look like.
If we required all studies to have 80% power, for instance, this would mean that fewer studies would be conducted (albeit larger ones), and it would also incentivize researchers to study effects already known to be large, harming innovation. So the existence of studies that were underpowered in retrospect is not a bad thing in itself, but I think most neuroscientists would agree that large and better-powered studies are something we need more of.
P.S. You might be wondering (as I did) why Nord et al.’s paper appeared in the Journal of Neuroscience when the Button et al. original was in Nature Reviews Neuroscience? It turns out there’s a rather strange answer to that, which I’ll discuss in an upcoming post.